
Vamos a hablar en este post de unos modelos que vienen muy a la mano cuando se quieren muchas respuestas, pero rápidas y baratas: los modelos de medidas repetidas.
Hay empresas que trabajan con muchas marcas y para cada marca tienen que decidir en qué puntos de contacto invertir y cuánto.
Normalmente, parten de un monto de dinero que tienen a su disposición para invertir en publicidad, y tienen que decidir cuánto invertir por marca y punto de contacto.
Así planteado puede parece algo sencillo, pero lo cierto es que no lo es.
Para tomar la decisión de manera objetiva deberíamos poder saber para cada marca y cada punto de contacto, cómo es la relación entre el dinero que se invierte y las ventas que se ganan (por hacer las historia más sencilla, vamos a suponer que el beneficio por cada unidad vendida es el mismo para todas las marcas).
¿Cómo llegar a dicha relación?
Una posibilidad sería haciendo un modelo econométrico para cada marca.
Tendríamos que disponer de series temporales de datos, con un histórico suficientemente largo (2 años al menos para poder aislar las estacionalidades), de todas las variables clave de marketing (distribución, precio, promociones, inversiones publicitarias, etc. (Tanto de las propias marcas como de las marcas de la competencia). Periodicidad del dato semanal o mayor.
¿Cuál es el problema de este enfoque? Si la empresa tiene más de 5 o 6 marcas, el análisis va a llevar mucho tiempo y va a ser además un análisis caro.
Además, a veces no se dispone de datos tan desagregados por marca (por ejemplo en variable de tracking).
Una alternativa es utilizar modelos de medidas repetidas. Os lo explico usando la fórmula:
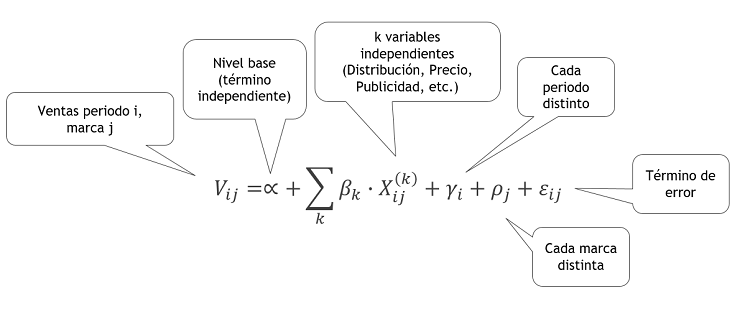
Lo que hacemos es como poner un modelo de regresión detrás de otro.
Imaginaros que tuviéramos un histórico de 2 años, con datos trimestrales, para 5 marcas. En realidad lo que estamos haciendo es construir una serie toda seguida, primero los dos años trimestre a trimestre de la marca 1, luego lo mismo de la marca 2, etc.
Y le decimos al modelo: vamos a suponer que la forma en que cada variable influye en las ventas es la misma, y que el nivel de las ventas va a variar en función de cada trimestre y en función de cada marca.
Como siempre, el analista tiene que consensuar con el cliente qué es lo mejor en función de las capacidades del primero. Si un cliente prefiere hacer un modelo para cada marca y está dispuesto a pagar lo que eso vale, ¡genial! Pero si no tiene tanto dinero, o datos tan desagregados, y sin embargo quiere poder predecir las ventas de cada marca, los Modelos de Medidas Repetidas son una buena opción.
Para mí, este es el arte que el analista tiene que tener. No es tanto ser un premio nobel como tener sentido común y aportar soluciones válidas.
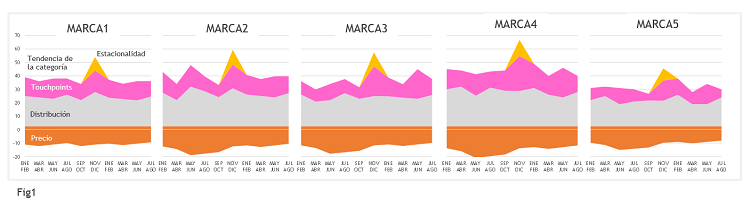
Gráficamente, lo que obtenemos es algo como lo que os muestro en la Fig1.
A partir del modelo, obtenemos la eficacia de cada punto de contacto y construimos las curvas que nos dan el ROI y los niveles de inversión mínima y máxima (Fig2).
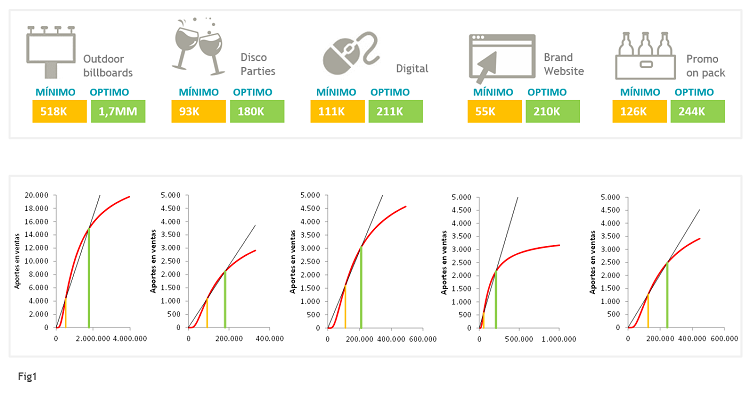
Con las curvas para cada punto de contacto y para cada marca, podemos resolver cuál será el reparto de inversión que maximizará las ventas de la compañía.
Así, una empresa con 5 marcas, que considere 10 puntos de contacto en los que invertir (TV, Display, Outdoor, Radio, Punto de Venta, Publicidad en Taxis,…), podrá saber si, por ejemplo, para la Marca1 merece la pena invertir en TV, mientras que para la Marca2 es mejor invertir en Punto de Venta. Y cuánto en cada caso.
Es una visión de Dirección General de Marketing y Dirección General de Compañía, donde lo principal es perseguir siempre el máximo beneficio global.
Este mismo enfoque se podría aplicar también a Países y Marcas, Regiones y Marcas, Tiendas y Marcas, etc.



Comentarios