Aunque para las compañías es muy importante conseguir nuevos clientes, lo es todavía más, evitar perder clientes que ya tienen. La forma natural de hacer crecer una empresa es mantener el nivel actual de clientes y crecer en la medida en que se capten nuevos clientes. Si se consiguiesen muchos clientes nuevos, pero a su vez se fueran perdiendo clientes existentes, sería como echar garbanzos en una bolsa con un agujero: no se llenaría nunca.
Por eso, tener modelos matemáticos que permitan estimar la probabilidad de que una persona solicite la baja de un servicio o producto es tan importante. Y cuanto mejor sea el modelo, más cerca estará la estimación de la realidad y mayor será la ganancia para la empresa.
Fases de este tipo de modelos (Fig. 1):
Fase 1: Proceso de tratamiento de datos. Ya conocemos el dicho aplicado al mundo de los datos “si metes basura, sacas basura”. Para que esto no suceda, habrá que invertir al inicio de un proceso de este tipo muchas horas para identificar errores en los datos, discriminar aquellas métricas que puedan ser clave para el análisis, graficar los datos, visualizarlos, etc.
Fase 2: Desarrollo del modelo de fuga. Los modelos que se suelen aplicar para la estimación de bajas son modelos logísticos, a partir de los cuales obtenemos la probabilidad de que un individuo determinado, i, solicite la baja de un servicio o producto en un momento t.
Fase 3: Revisión del modelo. Este tipo de modelos tienen que pasar una serie de tests estadísticos. Además, el modelo se valida sobre una muestra diferente a la que se utiliza inicialmente.
Fase 4: Implementación del modelo en los sistemas del cliente. Los modelos de probabilidad de baja son modelos que tienen que poderse implementar de manera ágil, para lo cual casi siempre se requiere la instalación en los sistemas del cliente.

Para la primera fase, en colaboración con el departamento de sistemas informáticos de la empresa que requiere el servicio, se desarrollarán unos procesos ETL (Extract, Transform and Load) que trabajarán con la información contenida en las bases de datos corporativas, y crearán todas las variables necesarias para la creación de los modelos. El dataset de variables significativas contendrá toda la información necesaria para la posterior implementación de los modelos y para la predicción de probabilidad de fuga para clientes actuales y futuros.
Las variables que pueden ser objetivo de ser introducidas como variables explicativas de la posible fuga dependerán en parte del sector de que se trate. Podemos ver un ejemplo en la Fig. 2.
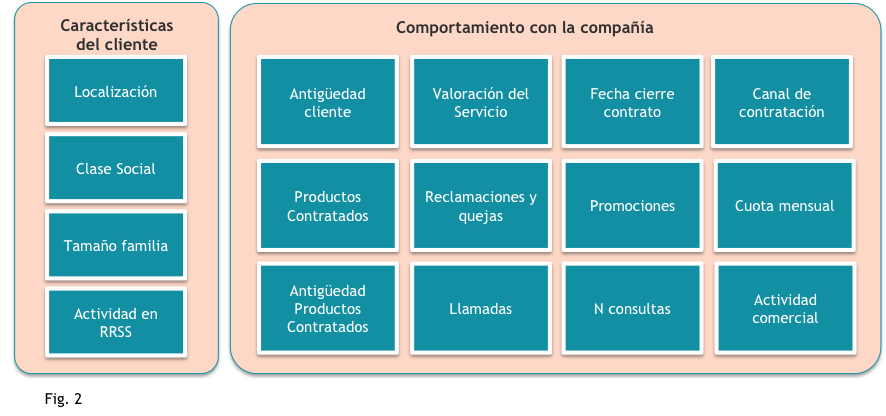
Algunas de estas variables tendrán que haber pasado por un proceso preliminar para ser creadas. Cómo detectar qué variables encajan en un modelo es un arte que el analista tiene que ir desarrollando poco a poco, a medida que va haciendo más y más modelos. Por ejemplo, en una base de datos original podemos disponer de la variable “Antigüedad del cliente”, una variable continua que recoge, por ejemplo, el número de días desde la fecha de entrada de dicho cliente. A través del algoritmo de discretización Interactive Grouping, podremos agrupar los valores de esta variable continua utilizando la variable dependiente, y así mejorando el poder predictivo de dicha variable.
Como lo que buscamos son modelos que midan la probabilidad de que un cliente abandone una compañía (fuga), deberemos recoger datos de los clientes en dos momentos diferentes: 1) hace meses, por ejemplo, recogeremos datos de todos los clientes que estaban en ese momento dados de alta, y 2) hoy veremos cuáles de aquellos siguen siendo clientes y cuáles no. La variable que queremos modelizar (explicar de qué otras variables depende y cuánto) será una variable dicotómica que tomarán valor 0 si la persona sigue siendo cliente o valor 1 si no lo es y por tanto ha sido una fuga.
Este tipo de modelos puede o no tener una herramienta de visualización ad-hoc. Hay empresas que sencillamente los implementan en sus sistemas y cada día saben qué clientes hay en riesgo y, por lo tanto, son candidatos a recibir ofertas o acciones de retención. Otras empresas, sin embargo, prefieren disponer además de una herramienta que muestre de manera sencilla las características de los clientes que se están dando de baja, de manera que puedan aprender y tomar decisiones más estratégicas.
Este post ha sido elaborado en colaboración con Conento.