
Se traduce Machine Learning como Aprendizaje Automático, que viene a significar que las máquinas deciden de manera automática.
¿Y cómo consiguen las máquinas decidir? A través de una serie de datos, y algoritmos que facilitan la toma de decisiones.
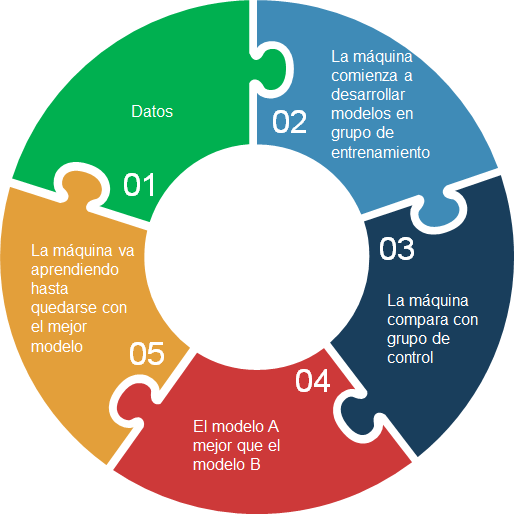
Vamos a verlo paso por paso:
- Imaginemos que queremos enseñar a una máquina a decidir si un chico joven es propenso a fumar.
- ¿Por dónde empezar? Vamos a coger un grupo de chicos jóvenes y vamos a determinar una serie de características que creemos a priori que puedan afectar al hecho de fumar o no fumar.
- Una vez tenemos claro qué vamos a recoger o preguntar, empezamos a recolectar los datos: características de cada joven (VARIABLES DE ENTRADA) y si fuma o no (VARIABLE DE SALIDA).
- Conseguidos los datos, le decimos a la máquina qué tipo de técnica estadística queremos utilizar (que nos va a decir cuál es la forma de la relación entre las variables de entrada y la variable de salida). La máquina va a correr esa técnica NO SOBRE EL TOTAL DE LOS DATOS, sino sobre un subconjunto suficientemente grande, denominado datos de entrenamiento.
- ¿Y cómo entrena la máquina? Va a ir probando modelos. Para ver cómo de buenos son va a utilizar el resto de datos que no se usaron (datos de test, que también tienen que ser una cantidad suficientemente grande), comparando modelo tras modelo, hasta quedarse con el que considere el mejor. Imaginemos que elige primero un modelo A ¿Cuánto de bueno es A? Supongamos que tiene un 60% de acierto cuando lo corre sobre los datos de test. Corre un segundo modelo B, hace lo mismo ¿Cuánto de bueno es B? ¿70%? Pues se quedaría con B. Esto una máquina es capaz de hacerlo millones de veces a toda velocidad, hasta quedarse con el mejor de todos los modelos.
- Finalmente, la máquina se quedará con un modelo, algoritmo o función que relaciona las variables de entrada con la variable de salida, y así, tomará las decisiones: le meteremos información de un joven determinado, y la máquina podrá hacer una suposición informada -con alta probabilidad de acierto- de qué tan propenso a fumar es.
Este ejemplo es un caso de algoritmo de aprendizaje supervisado, donde se tienen datos tanto de las entradas (características de los jóvenes), como de la salida del sistema (fuman o no).
Sin embargo, no siempre se dispone de los datos de salida. Los algoritmos de aprendizaje no supervisado son algoritmos donde solo conocemos las entradas. Lo que vienen a hacer este tipo de algoritmo es agrupar en función de la similitud de las variables de entrada. En el ejemplo anterior, haríamos grupos de jóvenes en función de sus características.
Algunas de las técnicas estadísticas que se usan en Machine Learning son:
- Árboles de decisión
- Random Forests
- Regresiones LASSO
- K-Medias
- Redes neuronales artificiales
- Redes bayesianas
- Etc
Pero, bueno, por hacerlo breve os dejo este sencillo diagrama:


Comentarios