
¿Quién no quiere tener un buen modelo de predicción que le anticipe las ventas de la compañía, en función de aquello que tenga planificado hacer? Todas las empresas lo quieren y lo tienen, de mejor o peor calidad.
En el caso de los bancos, suelen estar muy interesados en predecir cuánta gente va a contratar un producto determinado. Para poder desarrollar un buen modelo con este fin, lo primero que hay que hacer es sentarse con un grupo de personas del banco y dibujar entre todos un diagrama que sirva de esquema al analista, que luego irá haciendo las pruebas y construyendo el modelo. Dicho diagrama tiene que reflejar cómo funcionan las cosas, y la mejor manera de dibujarlo es empezar de atrás hacia delante: ¿Qué perseguimos? Vender ¿Tenemos varios canales de ventas o solo uno? Para cada uno de esos canales, ¿cuáles son las acciones que llevamos a cabo para incrementar las Ventas? ¿Qué acciones de la competencia pueden estar afectando? ¿Qué factores exógenos?… Cuánto más trabajemos este diagrama inicial, mejor y más rápido se construirán los modelos.
Se puede construir un modelo para cada canal de ventas y obtener el modelo global como suma de las partes. Esto requerirá más horas de trabajo puesto que pueden ser muchos modelos (uno por canal). También se puede usar un análisis Top-Down, que consiste básicamente en modelizar la cuota de los canales. Esta manera de hacerlo es más sencilla, aunque un poco menos precisa; pero tiene la gran ventaja de que se obtienen predicciones por canal. Cuando una empresa tiene varios canales de venta, las predicciones, y sobre todo la manera de construirlas, deberán obtenerse para cada canal, con sus características intrínsecas y determinadas.
Lógicamente, como pasa con todo aquello que tiene que ver con los análisis matemáticos, lo más importante a la hora de llegar a un buen modelo no va a ser tanto la metodología utilizada como la riqueza de los datos que se utilicen. Si la técnica que usamos son modelos econométricos o series temporales, el histórico de datos que vamos a necesitar deberá ser superior a dos años hacia atrás. Necesitaremos datos para todas las variables que hayamos decidido a priori que eran importantes. Por ejemplo, imaginemos que queremos predecir las contrataciones de préstamos personales, ¿qué variables pensamos que podrían ser importantes, en general, sin pensar en canales? Las condiciones de los préstamos, las promociones, la satisfacción de los clientes, la publicidad que hace el banco (tanto del propio producto como de la marca), la publicidad que hace la competencia, indicadores macroeconómicos, estacionalidad, etc. Para todas y cada una de dichas variables deberemos tener datos para el mismo periodo de tiempo y con el mismo nivel de desagregación.
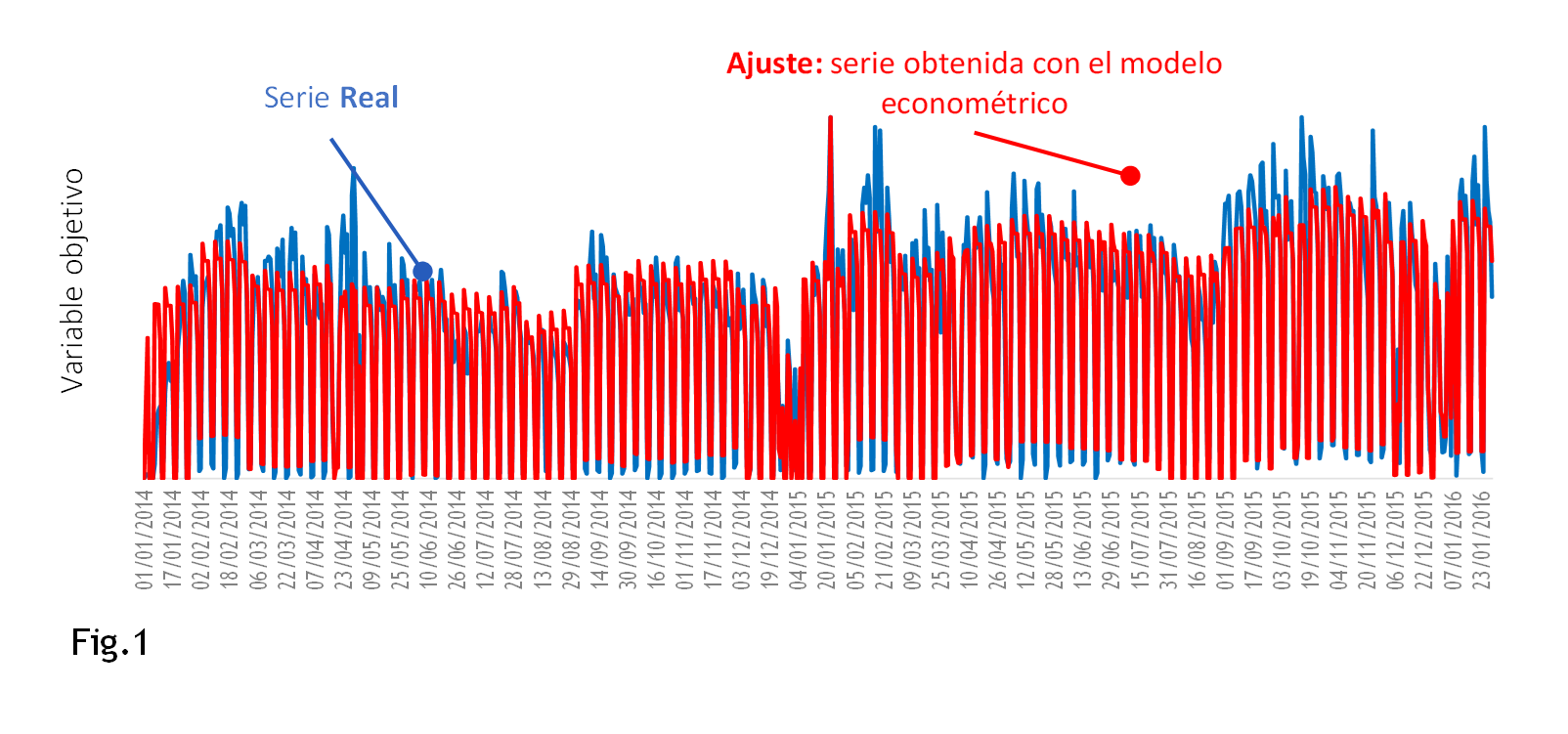
En la Fig.1 vemos un ejemplo de un modelo construido en base diaria (Fuente: Conento). La línea azul es el dato real y la línea roja es el modelo que conseguimos. A simple vista, uno puede decidir hasta qué punto la cercanía de las dos líneas le satisface, pero es muy importante conocer cómo se llega a la línea roja. Conocer cuáles han sido las variables admitidas por el modelo y hacerse muchas preguntas ¿Falta alguna de las que habíamos planteado como importantes? ¿Por qué? ¿Se puede solucionar? ¿Qué nos dice la estadística sobre la importancia de cada variable y el nivel de fiabilidad de dicho dato? Y, también, ¿ha utilizado el analista variables que consiguen mejorar el ajuste pero que no aportan aprendizaje ninguno?
Buenos modelos pueden ayudar a muchas empresas a vender más y de manera más eficiente. Por eso, metafóricamente, es importante no conformarse con mirar la casa por fuera, sino mirarla también por dentro y cerciorarnos de que las calidades son aquellas por las que hemos pagado. Antes de arriesgarnos a dar las primeras predicciones y esperar los resultados, podemos utilizar el propio modelo para comprobar qué tal lo hace. Imaginemos que tenemos un modelo diario basado en un histórico de 3 años, es decir, 1095 datos. Podríamos ajustar el modelo quitando los datos del último mes (modelo de entrenamiento), predecir después el mes restante, y comparar los datos reales de ese mes con las predicciones dadas por el modelo de entrenamiento.
Estos modelos predictivos se pueden necesitar para cubrir objetivos muy variados: estrategias globales del año (qué objetivos tenemos cada mes y ver si los vamos a conseguir); medición de la eficacia de las acciones que llevamos a cabo (por ejemplo, ver si nuestra inversión en medios ha funcionado); rentabilidad de dichas inversiones y maximización de la eficiencia; toma de decisiones en el corto plazo; etc. Si nos centramos en este último punto y queremos que nuestros modelos estén actualizados cada día, deberemos añadir a las predicciones una componente de Inteligencia Artificial, es decir, definir algún algoritmo que permita al modelo ajustarse por sí solo, sin necesidad de que el analista esté constantemente pendiente. Para mí, está es la clave de la diferenciación en lo que a modelos predictivos se refiere: combinar una muy buena metodología base con algoritmos de auto-aprendizaje que den velocidad al proceso.
Además, sabemos que valores intangibles de las empresas como la Reputación, la Experiencia o la Marca son palancas que mueven el negocio de las mismas (Fuente: Corporate Excellence). Hoy en día, el seguimiento de las redes sociales nos permite fijar sistemas de alarma para poder conocer de manera ágil y rápida si alguno de estos valores intangibles puede estar siendo dañado, repercutiendo de manera negativa en los resultados económicos de la compañía. Herramientas de Big Data conectadas a los modelos predictivos facilitarán medir las posibles consecuencias de movimientos sociales y anticiparse a buscar soluciones.
En un sector como el bancario, donde la competencia es atroz, donde cada día es importante en la toma de decisiones, tener unos buenos modelos predictivos, capaces de aprender por sí solos, y en tiempo real, va a resultar clave.



Comentarios