
Los sistemas de recomendación se utilizan para recomendar, por ejemplo, a personas que han hecho una compra determinada, qué otros productos podrían interesarle. Hoy en día lo utilizan casi todas las empresas de venta online, como por ejemplo Amazon (Fig1).
 Pero no solo se recomiendan productos para ser comprados, se pueden recomendar otras cosas como, por ejemplo, vídeos que te pueden interesar (Youtube), películas que te pueden gustar (Netflix), música que te apetezca escuchar (Pandora), personas que pueden ser tus amigos (Facebook), etc.
Pero no solo se recomiendan productos para ser comprados, se pueden recomendar otras cosas como, por ejemplo, vídeos que te pueden interesar (Youtube), películas que te pueden gustar (Netflix), música que te apetezca escuchar (Pandora), personas que pueden ser tus amigos (Facebook), etc.
Existen muchos tipos de modelos de recomendación. Yo os voy a contar algunos para que entendáis la lógica en la que se basan.
El modelo de recomendación más sencillo es el que consiste en recomendar aquello que es más popular (Modelo de Recomendación basado en Popularidad). Por ejemplo:
- Imaginemos que tenemos una base de datos con canciones que han escuchado 200.000 personas.
- Un recomendador basado en popularidad va a recomendar a cualquier persona lo mismo: la canción más escuchada de entre todas las que han escuchado las 200.000 personas.
- Por lo tanto, es un modelo no personalizado.
Un paso un poco más avanzado será precisamente conseguir cierta personalización de la recomendación. Por ejemplo, un modelo que se base en características que se conocen de los USUARIOS y de los PRODUCTOS, como:
- Históricos de compras
- Momento del día en que se han realizado las compras
- Características de los productos
- Etc.
Funciona como un modelo de clasificación (Fig2 – Modelo de Recomendación basado en Clasificación).
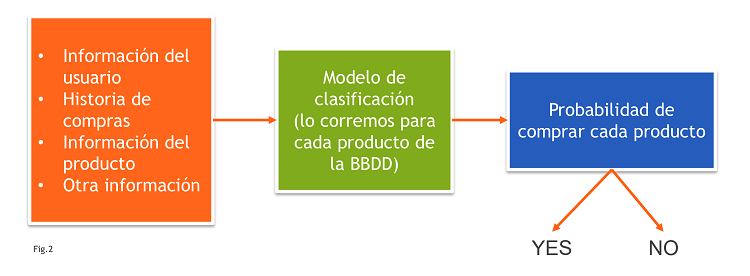
El problema que tienen estos recomendadores es la posible falta de datos tanto de los usuarios como de los productos.
La tercera tipología de recomendadores está basada en filtros colaborativos. Estos modelos tienen en cuenta lo que compraron otras personas que también compraron el producto que un usuario ha comprado. La lógica que hay detrás se puede resumir con una matriz que se crea para cada producto, la Matriz de Co-ocurrencia, que ilustra qué otro producto compraron los usuarios que compraron dicho producto (Fig3 – Modelo de Recomendación basado en Co-ocurrencia).

El modelo funciona mirando cada fila. Si, por ejemplo, nos centramos en la fila 1, que nos da información sobre todos los usuarios que compraron el producto 1 qué otro producto compraron, el recomendador dará como resultado aquel otro producto que esté en la casilla con el valor mayor. Imaginemos el siguiente ejemplo con 4 productos (Fig4):
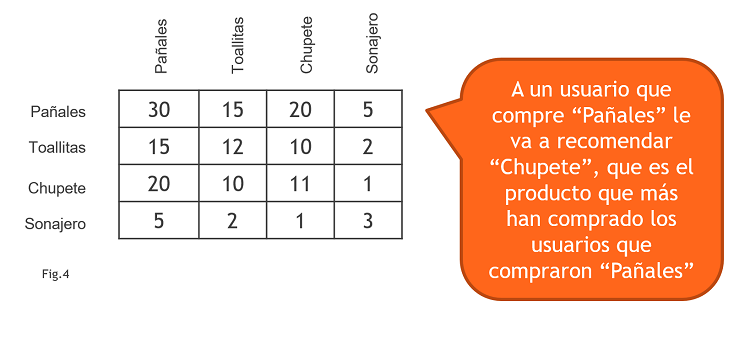
Siguiendo con este ejemplo de los 4 productos, imaginemos que hay mucha gente que compra pañales. Si queremos recomendar un producto a un usuario que ha comprado un sonajero, el producto que más se ha comprado junto a los sonajeros han sido los pañales. Y lo mismo pasa con las toallitas y los chupetes. ESTÁ AFECTANDO LA POPULARIDAD INDIVIDUAL DE CADA PRODUCTO (Fig5).
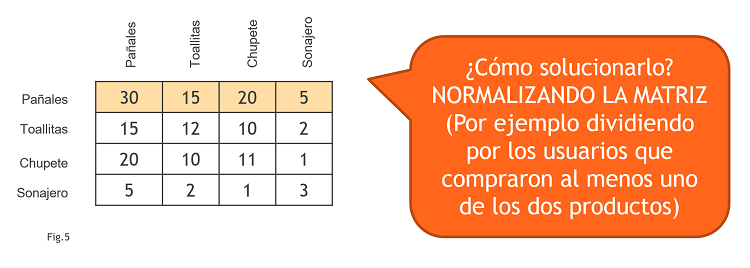
Este enfoque de la Matriz de Co-ocurrencia tiene dos problemas:
- No tiene en cuenta la historia de lo que el usuario ya compró (si acabas de comprar pañales pero ayer compraste un sonajero, te volverán a recomendar sonajeros, porque solo tiene en cuenta la compra que acabas de hacer).
- De la misma forma, si en una misma compra has obtenido dos productos (por ejemplo, pañales y sonajero), ¿qué producto te recomendaría?
La solución da lugar a los Modelos de Recomendación basados en Co-ocurrencia Ponderada. Lo vemos sobre el ejemplo anterior. Supongamos que un usuario compra pañales y sonajero en la misma compra. Lo que haremos será dar una valoración a cada uno de los productos restantes que tenga en cuenta no solo la situación de uno de ellos sino la de ambos. Por ejemplo, un simple promedio (Fig6).
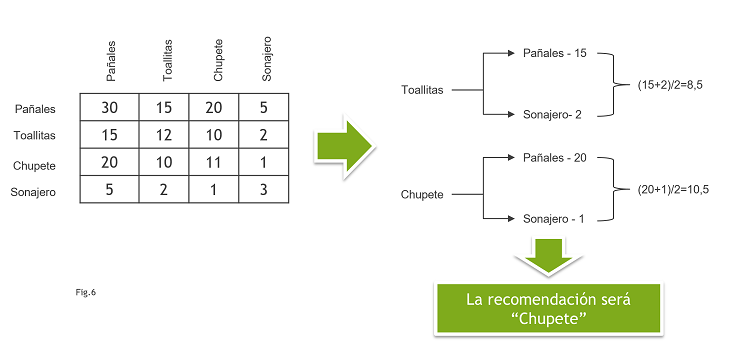
A pesar de que este modelo de Co-ocurrencia Ponderada mejora los dos anteriores, sigue teniendo puntos débiles:
- No tiene en cuenta el contexto (momento del día)
- No tiene en cuenta características del usuario (edad, género,…)
- Está limitado por la categoría de producto (si has comprado un producto para bebé solo te recomienda otros productos de bebé)
- Además, si empezamos a vender un producto nuevo, nunca sería recomendado porque nunca antes habrá podido ser comprado en pareja con ningún otro producto.
Para poder considerar características tanto de los usuarios como de los productos, lo primero que habrá que hacer será una lista de las mismas. Por ejemplo: Precio, Edad Recomendada, Tamaño, Para Jugar… Tanto para los productos como para los usuarios, rellenamos un vector con la valoración en ambos casos (Fig7 – Modelo de Recomendación basado en el Vector de Características):
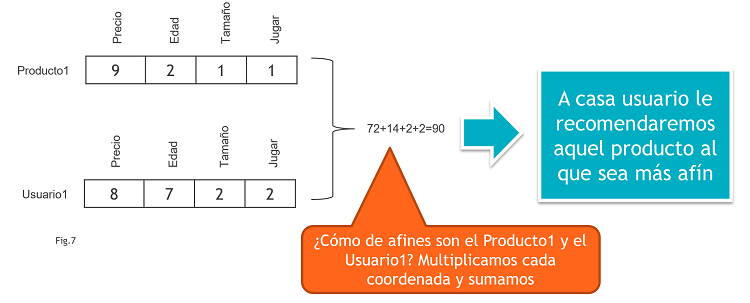
De la misma forma, si sacamos un producto nuevo, será fácil estimar la valoración dadas las características y, a partir de ahí, desde el momento inicial podría ser un producto a recomendar.
El único caso que sigue sin poderse solucionar es si entra una persona que nunca antes ha hecho una compra y no sabemos cómo valora las diferentes características de los productos. Siempre, en estos casos ya extremos, se podría acudir a métodos globales como el de la Popularidad. La mejor solución es combinar los diferentes métodos según cuál sea la situación particular en cada caso.
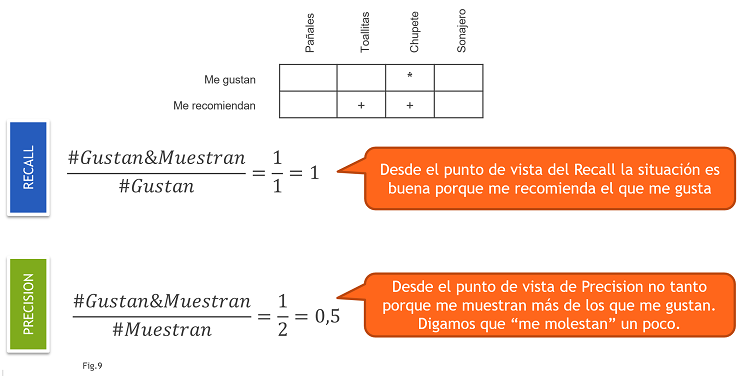
Para evaluar un modelo de recomendación se definen dos métricas (Fig8):
- RECALL: de todos los que me gustan, cuántos me ha mostrado el recomendador.
- PRECISION: de todos los que me ha mostrado el recomendador, cuántos me gustan.

Este tipo de pruebas se hacen probando el recomendador con un conjunto de entrenamiento y comprobando con un conjunto de test. Volviendo a nuestro ejemplo, supongamos que a nosotros nos gustan los Chupetes (indicamos “Me gusta” con un *) y el recomendador nos muestra Toallitas y Chupetes (indicamos “Me recomiendan” con un +). Vemos los cálculos en la Fig9.
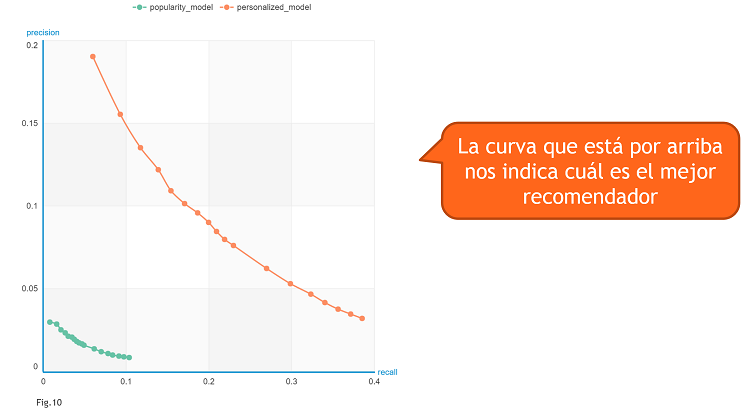
Por último, para comparar los recomendadores se grafica Precision vs Recall (en general para un grupo test – Fig10 – Curva Precision-Recall). Tal y como indicamos en la figura, la curva que está por encima nos indica cuál es el mejor recomendador.



Comentarios