
El Procesamiento de Lenguaje Natural se utiliza para clasificar de forma automatizada los textos no estructurados en un conjunto de temáticas.
Por ejemplo, poder determinar que un texto como «No compro el producto en este establecimiento porque es más barato en otros sitios» pertenece a la temática «Calidad-Precio».
En Conento utilizamos este tipo de modelos de Procesamiento de Lenguaje Natural cada vez en más ocasiones. Por ejemplo, en el análisis y clasificación de las respuestas abiertas en los cuestionarios de investigación; para estructurar información textual en las redes sociales o para hacer análisis de sentimiento; para clasificar documentos; para procesar conversaciones de Call Center, previamente codificadas en texto o mediante software de reconocimiento de voz; etc.
En lugar de la metodología de Clasificación Basada en Diccionario, en Conento utilizamos Clasificación Semi-Supervisada con Machine Learning. La razón para ello es que, a pesar de que la Clasificación Basada en Diccionario es más fácil de implementar y quizás más intuitiva, tiene dos desventajas importantes:
- Tiende a sobre-ponderar el impacto de determinadas palabras
- No es muy sensible al efecto de expresiones complejas o negaciones
Sin embargo, la Clasificación Semi-Supervisada con Machine Learning, cuyo único punto negativo es quizás el hecho de requerir mayor capacidad de cómputo, tiene tres claras ventajas:
- Puede recoger el impacto de expresiones complejas, negaciones, etc.
- Facilita la incorporación de nuevos términos o expresiones, añadiendo más textos clasificados a la base de entrenamiento
- Tiene una tasa de acierto de más del 70%
¿Cómo funciona la Clasificación Semi-Supervisada con Machine Learning? Lo vemos en la Fig1, que os resumo a continuación de manera sencilla:
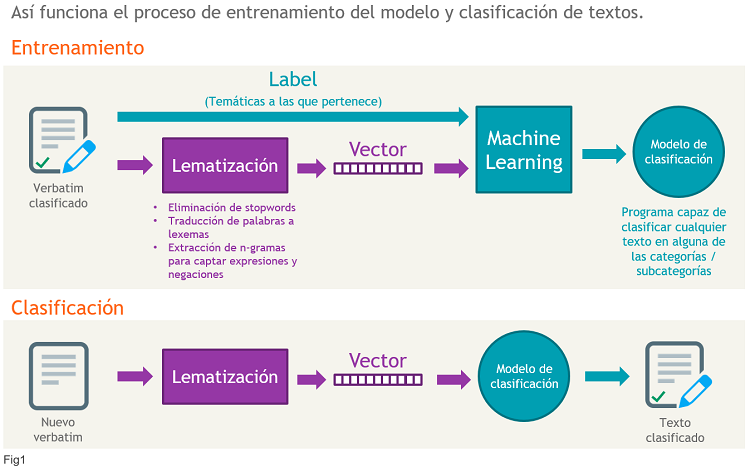
- Primero aprendemos con un conjunto de entrenamiento tratado por expertos en la materia que se quiera clasificar y en el lenguaje en sí mismo (linguistas, por ejemplo). Después ya utilizamos el algoritmo para clasificar
- En el conjunto de entrenamiento empezamos con la Lematización (os hablé de ella en el post «MÉTRICA DE MARCA EN REAL TIME»), que consiste en simplificar y homogeneizar los textos
- Después, una vez tenemos todos los textos, construimos un vector con todas las palabras que aparecen en todos ellos (¡imaginaros qué largo es el vector!)
- Los expertos van analizando cada texto y cada variable del vector, confirmando si esa variable está o no en cada texto. De esta forma tenemos particularizado el vector para cada texto
- Los expertos clasifican cada texto
- Tenemos ya los vectores para cada texto, con ceros y unos, y la clasificación final
- Aplicamos un modelo logístico que nos dice qué importante es cada una de las variables del vector en cada temática
Como seguro que no lo habéis comprendido (me pasó a mí lo mismo cuando me lo contó Gonzalo), os pongo el ejemplo que él me puso y que me abrió el entendimiento.
Imaginad que queremos clasificar los siguientes 3 textos en función de si en ellos se habla o no de bancos:
- A «La hipoteca no me gusta»
- B «Me gusta el helado»
- C «Las hipotecas son una estafa»
Primero, lematización:
- A «Hipoteca Gustar»
- B «Gustar Helado»
- C «Hipoteca Estafa»
Construimos un vector con las variables todas las palabras:
- X1=Hipoteca
- X2=Gustar
- X3=Helado
- X4=Estafa
Los expertos analizan el vector (X1,X2,X3,X4) para cada texto y lo clasifican:
- A «Hipoteca Gustar» (1,1,0,0) – SÍ BANCA
- B «Gustar Helado» (0,1,1,0) – NO BANCA
- C «Hipoteca Estafa» (1,0,0,1) – SÍ BANCA
Si ahora llegara un texto a ser clasificado de manera automática, por ejemplo:
- D «¡Ya tengo hipoteca!»
El motor de clasificación sabría que por tener la palabra hipoteca la probabilidad de estar hablando de banca es alta, puesto que arriba veíamos que en los dos casos en que se hablaba de banca estaba esta palabra.
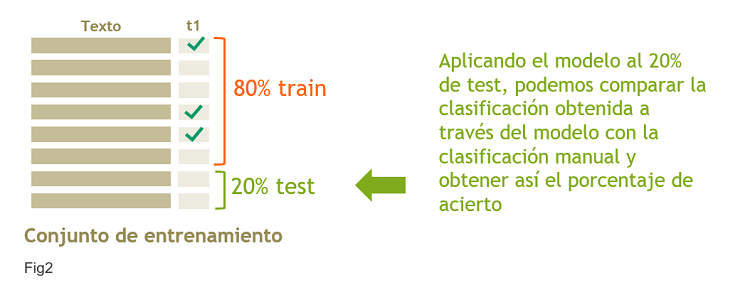
¿Cómo se mide la precisión del modelo de Procesamiento de Lenguaje Natural de este tipo? Como tenemos todos los textos clasificados de forma manual, cogemos unos cuantos, aplicamos el modelo y vemos qué tal clasifica (Fig2).
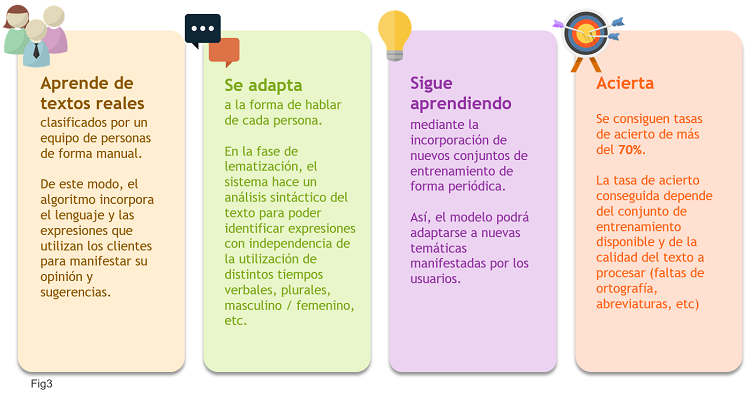
En la Fig3 resumimos las características de este tipo de modelos:
- Aprende de textos reales clasificados por personas de manera manual
- Se adapta a la forma de hablar de cada persona
- No es estático. Podemos seguir alimentándolo con nuevos textos.
- Tiene un % de acierto alto.
Comentar que se pueden configurar muchos conectores para integrar los modelos de clasificación de Procesamiento de Lenguaje Natural en los sistemas del cliente:
- Procesamiento Batch: se habilita un FTP seguro donde se guarda periódicamente un fichero con textos y devuelve los textos clasificados.
- API Rest: se expone una API Rest que permite al cliente integrar fácilmente los modelos de procesamiento de texto en otros sistemas
- Procesamiento Real Time: también mediante API Rest pero con un despliegue de hardware adecuado para sistemas de tiempo real.
- Solución On-Premise: los modelos de clasificación se integran en los sistemas del cliente. El sistema está basado en software libre y no requiere la adquisición de licencias de software adicionales.
Por último, os dejo con 3 ejemplos hechos por Conento de aplicación de este tipo de técnicas:






Comentarios