
Si alguna vez tenéis ganas de ejecutar de manera rápida y sencilla árboles de decisión en Python, os dejo unas indicaciones.
- Cómo poder ejecutar Python en el ordenador.
Lo primero que tienes que hacer es instalarte un programa que se llama Anaconda. Buscas cuál es tu sistema operativo y seleccionas Python 3.5. Te lo bajas y lo ejecutas dejando las opciones de instalación como vienen por defecto.
Cuando abras Anaconda verás enseguida que se ve un programa que se llama Spider, que es el que tienes que abrir para escribir y ejecutar el programa en Python para hacer árboles de decisión.
Una vez abras Spider puedes escribir el programa que te explico en el siguiente epígrafe.
- Programa para desarrollar árboles de decisión
Os dejo el código, explicando qué hace cada cosa, y señalando las cosas importantes.
#Primero hay que llamar a unas librerías que el programa necesitará.
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
import os
import matplotlib.pylab as plt
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
import sklearn.metrics
#Después, indicamos en qué directorio vamos a trabajar. Aquí ponéis entre paréntesis vuestro directorio.
os.chdir(«C:\TREES»)
#Cargamos el fichero de datos. Formato en Excel, csv.
AH_data = pd.read_csv(«fichero_datos.csv»)
#Eliminamos los datos con valores missing porque Python no puede hacer árboles con datos missing
data_clean = AH_data.dropna()
#Para comprobar que se ha leído bien, podemos lista las variables en el fichero y sacar los principales estadísticos
data_clean.dtypes
#Principales estadísticos
data_clean.describe()
#Indicamos las variables predictoras y debajo la variable objetivo. Cada uno con los nombres de las variables que tenéis en el fichero csv.
predictors = data_clean[[‘VARPRED1’, ‘VARPRED2′,’VARPRED3’]]
targets = data_clean.VAROBJ
#Creamos la muestra de entrenamiento y de test, tanto para predictores como para la variable objetivo, siendo test el 40%
pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, targets, test_size=.4)
#Comprobamos el tamaño de las diferentes muestras (pred=predictora; tar=target, objetivo). La salida en cada caso es una pareja de datos: el tamaño de la muestra y el número de variables
pred_train.shape
pred_test.shape
tar_train.shape
tar_test.shape
#Construimos el árbol con los datos de entrenamiento
classifier=DecisionTreeClassifier()
classifier=classifier.fit(pred_train,tar_train)
#Predecimos para los valores del grupo Test
predictions=classifier.predict(pred_test)
#Pedimos la matriz de confusión de las predicciones del grupo Test. La diagonal de esta matriz se lee: arriba a la izda True Negatives y abajo a la dcha True Positives.
sklearn.metrics.confusion_matrix(tar_test,predictions)
#Sacamos el índice Accuracy Score, que resume la Matriz de Confusión y la cantidad de aciertos.
sklearn.metrics.accuracy_score(tar_test, predictions)
#Para dibujar el árbol hay que importar otra serie de cosas
from sklearn import tree
from io import StringIO
from IPython.display import Image
#Pintamos el árbol
out = StringIO()
tree.export_graphviz(classifier, out_file=’treeMacarena.dot’)
IMPORTANTE: el árbol que hemos pintado se llama treeMacarena pero no aparece en Spyder. Para conseguir la imagen tenéis que hacer una serie de pasos que os explico a continuación.
- Visualizar árboles de decisión ejecutados en Python
Lo primero que tenéis que hacer es instalaros un programa que se llama Graphviz. Si tenéis Windows, tenéis que ejecutar el fichero graphviz-2.38.msi. La instalación tiene dos cosas importantes que tenéis que recordar. Os dejo un fichero en inglés donde viene bien explicado: Installing Graphviz and pydotplus
Después, tenéis que iros a «Símbolo del sistema» y colocaros en el directorio donde hemos estado trabajando. En nuestro ejemplo: C:\\TREES.
Y tenéis que escribir: dot -Tpng treeMacarena.dot -o treeMacarena.png
Esto lo que hace es llevaros el árbol que habéis hecho en Python a una imagen en formato png, de nombre «treeMacarena» y que encontraréis en C:\\TREES.
Os pongo un ejemplo de una imagen correspondiente a un árbol con dos variables predictoras.
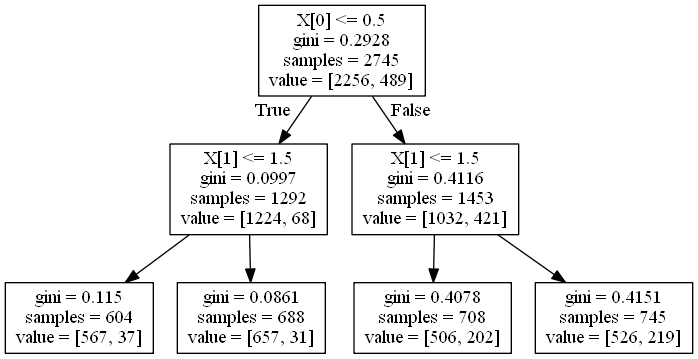
- Interpretación del árbol
Os cuento un poco qué es cada variable y cómo os aconsejo leer el árbol.
Variable objetivo: Fumador frecuente
Variables explicativas:
- X(0)=Consume alcohol con frecuencia (1=SI/0=NO)
- X(1)=Género (1=Hombre/2=Mujer)
Empezamos arriba y vamos bajando:
- La primera cajita (nodo) lo que nos dice es que tenemos 2754 individuos de la muestra, de los cuales 2256 no son fumadores frecuentes y 489 sí.
- De las dos cajitas siguientes, la de la izda nos dice que de lo 2754 individuos de la muestra, 1292 no consumen alcohol con frecuencia (viene de True de arriba, es decir, X(0)<=0.5, es decir, X(0)=0) y de esos 1224 no son fumadores frecuentes y 68 sí.
- La cajita de la dcha nos dice que de los 2754 individuos de la muestra, 1453 consumen alcohol con frecuencia y de esos 1032 no son fumadores frecuentes y 421 sí. Esto ya parece indicarnos que el hecho de consumir alcohol con frecuencia favorece ser un fumador frecuente.
- Por último tenemos el tercer nivel. La cajita de la izda del todo lo que nos dice es de los 2754 individuos de la muestra, 604 son hombres que no consumen alcohol con frecuencia y de ellos 37 no son fumadores frecuentes. La siguiente cajita nos indica que 688 son mujeres que no consumen alcohol con frecuencia y de ellas 31 no son fumadoras frecuentes. La tercera cajita nos indica que tenemos 708 hombres que consumen alcohol con frecuencia, de los cuales 202 son fumadores frecuentes. Y por último, la cuarta cajita nos dice que tenemos 745 mujeres que consumen alcohol con frecuencia, de las cuales 219 son fumadoras frecuentes. Mirad esta tabla resumen:
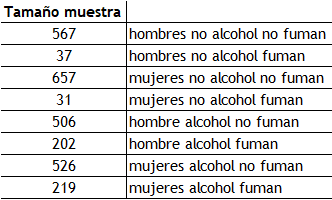
De esta tabla podemos inferir (sumando hombres que fuman y mujeres que fuman) que la probabilidad de fumar siendo hombre es de 0,18 y la probabilidad de fumar siendo mujer es de 0,17. Por lo tanto, parece que el género no es tan determinante para ser fumador como el hecho de consumir alcohol (0,28 probabilidad de fumar si consumes alcohol y 0,05 si no consumes alcohol).



Comentarios