
Los nombres de cada puesto de trabajo a menudo no son precisos o no definen con exactitud el trabajo que realmente se hace. Esto también sucede, y quizás incluso más, en puestos relativamente nuevos como son científico de datos o ingeniero de Machine Learning.
Estuve escuchando este debate en el canal de YouTube DeepLearningAI y me decidí a escribir un post resumen del mismo. No es la transcripción del debate, sino como si yo lo hubiera escuchado y lo contara con mis palabras. Ya sabéis que soy fan de la ciencia de datos y el Machine Learning.
Lo primero que quiero hacer es presentaros a los tres participantes, por orden de intervención:
.- Aishwarya Srinivasan, que lidera AI & ML Innovation en IBM. 200K seguidores en Linkedin.
.- Kate Strachnyi, fundadora de DATAcated y Datacated Academy. 150K seguidores en Linkedin.
.- Steve Nouri, AI Expert and Committee Member en ISO, escritor en Forbes Tech Council y fundador de AI4Diversity. 400K seguidores en Linkedin.
Impresionantes los tres. Merece la pena echar cada semana un vistazo a sus posts, aunque sea rapidito. Marcan tendencia.
La moderadora es Sandhya Simhan, directora de marketing de Deeplearning.ai en el momento de la entrevista, pero ahora ya es directora de marketing en Facebook.
La primera pregunta que les hace, después de las presentaciones, es cuál es la diferencia entre ambos roles (Científico de Datos vs. Ingeniero de ML).
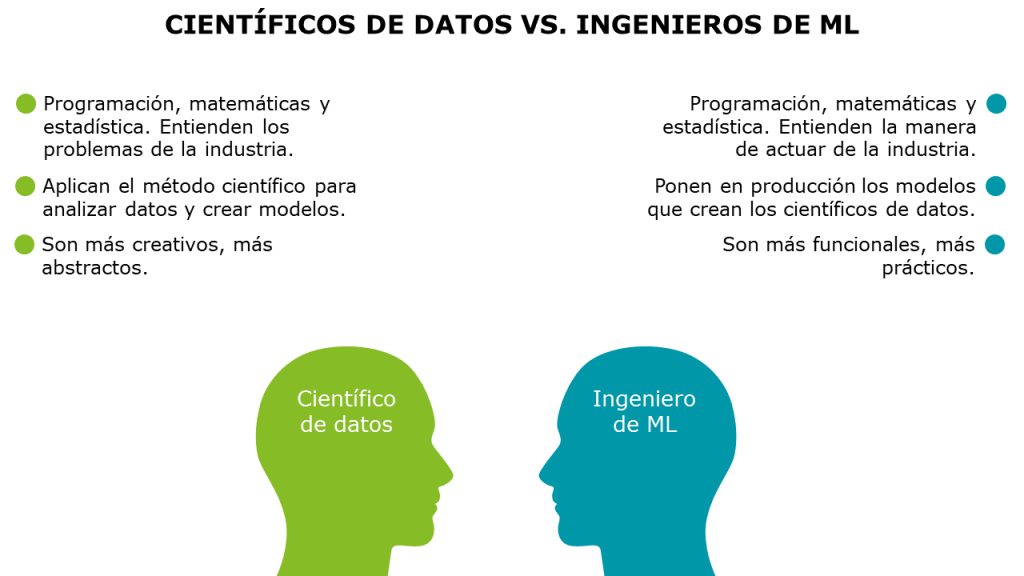
.- Aishwarya dice que un científico de datos no solo tiene que saber temas de programación, matemáticas y estadística, sino que además tiene que conocer la industria en la que se está aplicando la ciencia de datos. Sin embargo, un ingeniero de Machine Learning, además de saber programación, matemáticas y estadística, no necesita conocer tanto la industria.
.- La respuesta de Kate me gustó mucho. Ella dice que un científico de datos es alguien que aplica correctamente el método científico a los datos. Realizan análisis exploratorio de datos y obtienen información. El ingeniero de ML es alguien que toma los modelos creados por el científico de datos y los hace funcionar en un entorno de producción muchas veces a escala.
.- Steve comenta que un científico de datos es más como un científico, que experimenta más y es más creativo. Mientras que los ingenieros de ML se encargan más de que las cosas funcionen y estén operativas. [Maca]: Es verdad que es como la diferencia entre un matemático y un ingeniero. El primero es más abstracto y el segundo más práctico. El matemático tiene que ser creativo para tener ideas felices (ver lo que no se ve a simple vista), mientras que el ingeniero es más funcional, y piensa en base a procesos.
He resumido en una diapo mi conclusión:
Tras escuchar las tres contestaciones anteriores, Shandya pregunta a Steve por qué cree que todavía no están del todo claras ambas definiciones, a pesar de llevar ya 10 años hablando de ellas.
Steve comenta, en primer lugar, que vivimos en un entorno laboral que está en permanente evolución y cambio. Por tanto, no es algo que solo atañe al campo de la ciencia de datos o de la Inteligencia Artificial (IA). Cuando se empezaron a usar las definiciones de científico de datos y de ingenio de ML, eran términos genéricos, que luego se fueron complicando a medida que las tareas que se asignaba a dichos roles se hacían más y más complejas, dando lugar a la aparición de otros muchos roles como, por ejemplo, hablar de profesional de los datos. Y esto va a seguir cambiando. Además, estos papeles van a depender también del tamaño de las empresas y del tipo de industria. Steve no cree que esto sea algo que de verdad se pueda estandarizar.
Aishwarya añade que tampoco 10 años son tantos cuando hablamos de un nuevo campo que emerge, y que en parte son las propias empresas las que deciden qué definición dar a cada rol.
¿Cómo es un día típico de trabajo para cada perfil?
Aishwarya dice que un científico de datos tiene que trabajar en la construcción de los modelos, tiene que mancharse las manos con los datos, entender bien cuál es el problema de negocio a resolver y cómo lo van a hacer, revisando una y otra vez la calidad de los datos y que no haya sesgos. Trabajan casi todo el tiempo con los datos, también analizando cuál será el mejor algoritmo para utilizar, y comprobando que la elección final funcione bien. Esto implica que los científicos de datos son personas a las que les gusta investigar y que saben matemáticas y estadística. Por otra parte, los ingenieros de ML van a recoger estos modelos que han finalizado los científicos de datos y los van a llevar a producción, van a intentar escalarlo, de forma que las personas puedan utilizarlos en sus teléfonos móviles o en sus ordenadores. Tienen que conocer muy bien la manera de trabajar de las organizaciones.
Shandya comenta que, tras escuchar a Aishwarya, se podría decir que los científicos de datos son los que extraen el oro y los ingenieros de datos son los que lo hacen accesible a los demás.
Sigue el debate con la pregunta sobre la progresión de las carreras de estos perfiles.
Kate responde que en ciencia de datos sucede como en muchos otros casos, que a lo largo de tu carrera profesional tienes que elegir si tomar la dirección hacia la gestión o seguir contribuyendo de forma individual. Pone como ejemplo al científico de datos, que muchas veces empieza como becario, después crece hasta nivel científico de datos sénior, y es en este momento cuando tiene que elegir si pasar a ser director de equipos, o si prefiere seguir especializándose a alto nivel en ciencia de datos y seguir contribuyendo de forma individual. Desde que empezó hasta que llegó a un nivel sénior, también ha ido mejorando sus capacidades y teniendo mayor responsabilidad; pasando de llevar una parte de un proceso, a dirigir procesos de principio a fin; y aprendiendo mucho sobre los negocios y cómo resolver problemas específicos de cada negocio. En el caso de los ingenieros de ML, suelen comenzar aprendiendo un lenguaje de programación, como Python, que es muy conocido; aprender algo sobre ingeniería informática: cómo se deben estructurar los datos, qué algoritmos hay, … Y, generalmente, han estudiado un grado en informática o en programación. Los roles iniciales de estos perfiles pueden ser desarrollador de software o ingeniero informático, hasta llegar a ser un ingeniero de ML. Llegados a este punto, igual que sucedía con los científicos de datos, aquellos que tengan capacidades de liderazgo podrán seguir hacia puestos de gestión en compañías, pero también podrán ser consultores independientes, freelancers, o profesores de las nuevas generaciones tanto de científicos de datos como de ingenieros de ML. Hay muchas oportunidades.
¿Y qué habilidades hay que tener para elegir uno u otro camino?
Steve comenta que no existe una respuesta general, válida para todos. Va a depender de las preferencias individuales de cada uno y de los planes individuales de futuro. También va a depender de la industria en la que la persona quiera trabajar, ya que los requerimientos por industria son diferentes. Si eres una persona «techi», te va a gustar una compañía también «techi», que va a demandar un nivel alto de conocimiento. Además, en la medida que ya tenga la persona conocimiento previo de una industria como finanzas o biomedicina, también facilitará que trabaje en esas industrias, que requieren perfiles que conozcan bien el negocio. Dicho esto, hablando de habilidades específicas a cada role, los científicos de datos tienen que ser capaces de manejar datos, conocer SQL (no está en absoluto muerto); conocimiento de matemáticas y estadística es necesario en ambos perfiles, aunque algo más avanzado en los científicos de datos. Y también es importante la visualización, en ambos perfiles y para cualquiera que quiera mostrar datos de manera comprensible. De manera similar, los ingenieros de ML tienen que manejar mejor que los científicos de datos la programación orientada a objetos, así como la codificación avanzada y también Github.
¿Y qué estudios hay que tener en cada caso?
Kate afirma que la respuesta obvia es una carrera en ingeniería informática, programación, física o estadística, pero sin embargo cada vez más las grandes empresas no están exigiendo estas carreras, ni siquiera que tengas estudios universitarios. A lo que más importancia dan es a tu experiencia y a lo que eres capaz de hacer. Tener proyectos interesantes y poder mostrarlos. Además, vivimos en una era con acceso a Bootcamps, a libros de textos, a cualquier tipo de información en Google. De hecho, la mayoría se pasan el día googleando en busca de información, sobre todo cuando se han atascado en algo. Hay esperanza para aquellos que no tienen un background técnico.
Una de las características que distingue a los ingenieros de ML es ser capaces de poner en producción los modelos y escalarlos (ML Ops) ¿Cuánto debe saber de este tipo de funciones el científico de datos vs. el ingeniero de ML?
Aishwarya vuelve a matizar que cada empresa es diferente, y pone el ejemplo de su equipo donde, cuando trabajaba como científico de datos, no separaban a los que trabajaban ingeniería de datos o visualización o ML Ops. Se trataba de unicornios capaces de hacer cualquiera de estos trabajos, así que podías ver un científico de datos haciendo ML Ops. Salvo que el puesto lo especifique, muchos de estos trabajos pueden ser atendidos por diferentes perfiles. Lo importante es, entre todos, tener el conocimiento necesario para resolver el problema específico que se trate. Por ejemplo, un tema de ética de la IA va a necesitar tener en el equipo diferentes perfiles como un filósofo o un psicólogo, que nos ayuden a entender el posible efecto negativo de un sistema de IA. ML Ops es algo muy específico que puede o no ser realizado por un científico de dato. En general, dependiendo de la empresa puede haber perfiles mixtos o perfiles muy específicos como ingenieros de datos, ingenieros de ML o gente exclusivamente encargada de las bases de datos. Lo importante para una persona que quiera trabajar de científico de datos es que no se fije solo en el título de las ofertas de trabajo, sino en la descripción del puesto. Que busque en Linkedin qué otras personas hay en el equipo y que hable con ellas. También con personas en otras compañías, en equipos similares. Poder preguntarles cómo es su día a día y si hacen o no ML Ops.
¿Qué consejo le darías a una persona que, no teniendo un perfil de científico de datos o ingeniero de datos, quiere comenzar a trabajar en este mundo?
Aishwarya empieza poniendo el ejemplo de desarrolladores de aplicaciones webs. No se trata solo de la programación de la página, sino también de cómo los usuarios van a interactuar con ella, si les resulta suficientemente atractiva, si es fácil de usar. Toda es información le llega al desarrollador y, por lo tanto, es parte del trabajo. De forma similar sucede cuando hacemos ciencia de datos o modelos de ML. En su equipo hay gente que viene de investigación operativa, o que tienen una especialidad en salud. Cuando han trabajado en proyectos de salud, por ejemplo, esa persona en su equipo con este background ha ayudado a entender mejor los datos y a ampliar la perspectiva. Como dice Andrew Ng, vamos a resolver mejor los problemas en la medida en que los entendamos mejor y nos centremos en los datos, y aquí ayuda mucho tener un amplio abanico de perfiles. Comenta también que han tenido a veces fallos en los sistemas por no entender los datos bien. Remarca que es importante incorporar perfiles con diferentes capacidades en variedad de industrias, que no necesariamente programarán en Python u otro lenguaje de programación, pero que aportarán mucho a los proyectos. [Maca]: El único problema que veo aquí es de dónde sacar tantos perfiles expertos en tantas industrias. En una empresa de servicios profesionales grande, como Deloitte, no va a haber ningún problema, pero ¿qué harán las consultoras de tamaño mediano o pequeño? ¿Estos perfiles expertos los pondrán los clientes en algunos casos?
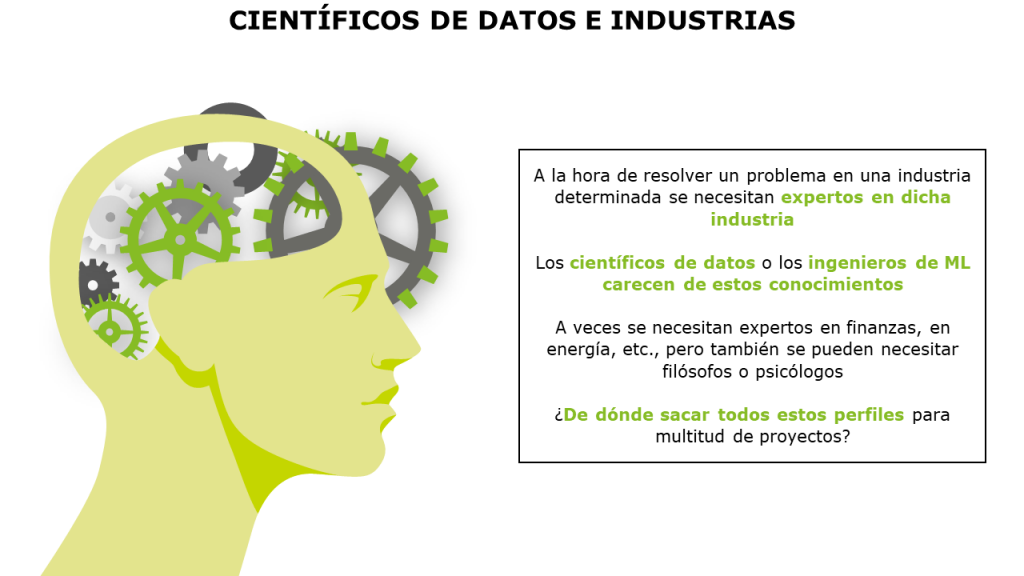
Shadya afirma que en otro evento comentaron a este respecto que a lo que se tiende es a partir del «expertise» de las personas en cada industria, enriquecerlo con IA, y no al revés. Así las personas mejoran su carrera, llevándola un paso adelante.
También hay personas que sí están formadas en carreras técnicas, pero quieren pasar a ser científicos de datos ¿Qué es lo que en general se echa en falta en estos casos?
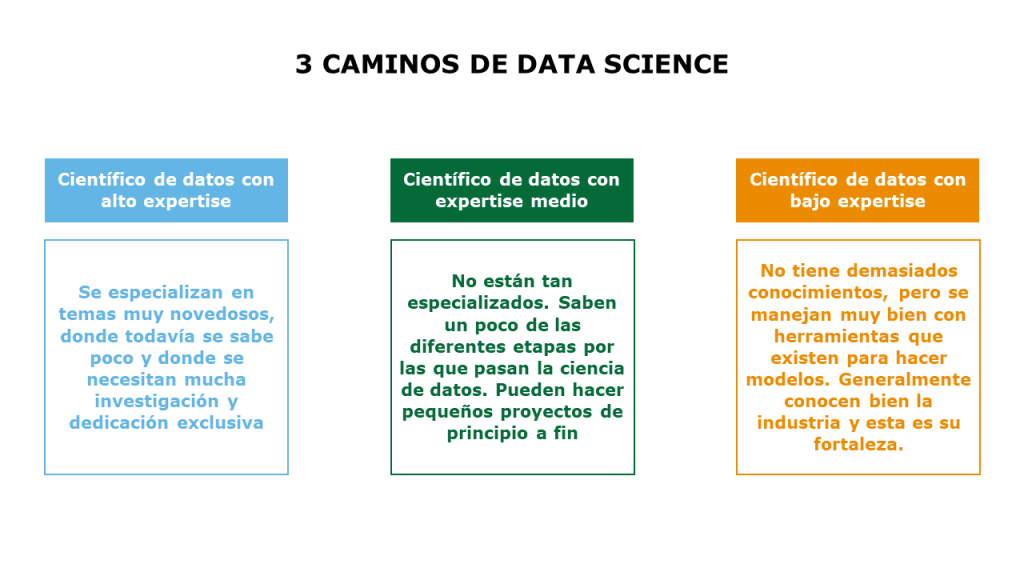
Steve responde que es algo que está sucediendo mucho porque IA y ciencia de datos está muy de moda. Hay personas que hacen este cambio rápidamente porque creen que va a ser algo fácil y vienen ya de haber estado años estudiando una carrera larga. Aprenden pequeñas cosas de ML, como algunos algoritmos que prueban con un conjunto de datos, obtienen los resultados y se olvidan de cosas importantes. Por ejemplo, unos alumnos que conectaron un algoritmo a un conjunto de datos y creían que eso era ciencia de datos. Hay que enseñarles los problemas reales con los que se van a encontrar. Casos en que los datos no están bien. Una de las carencias de estos perfiles es, por ejemplo, la habilidad para limpiar los datos. También a veces carecen de base en matemáticas y estadística para comprender qué hay dentro del algoritmo y no tratarlo como caja negra. Una vez comprendido el interior, sí se puede utilizar auto ML para optimizar el algoritmo.
¿Y cuál sería el camino de aprendizaje, con qué recursos?
Steve continúa afirmando que depende mucho de cada persona. Él, por ejemplo, comparte muchos recursos en LinkedIn que son recursos al alcance de todos. A algunas personas les encanta leer libros. Otros prefieren ver videos en YouTube o apuntarse a un curso de Coursera. Las personas tienen diferentes preferencias. Algunos preferirán escuchar podcasts. Lo importante es asegurarse de obtener la información y los recursos más recientes y fáciles de entender. Los libros a lo mejor te dan más detalle, pero menos actualidad. Los blogs también son muy interesantes y están menos desactualizados que los libros. Contar por supuesto con Google y seguir a personas a las que se conoce y que ya sabes que funcionan.
Kate añade que cada persona tiene sus métodos de aprendizaje. Para muchos será una combinación de todos los que ha comentado Steve. La gente que quiere trabajar en este tipo de proyectos no siente escasez de recursos sino todo lo contrario. Hay muchísimos cursos diferentes, de todo tipo. Creo que lo importante es que cada persona tenga su propio método de aprendizaje y elija aquel curso que mejor se adapte a sus objetivos. No es lo mismo querer tener un trabajo en los próximos meses y ser esa tu prioridad, que querer ser el mejor científico de datos o el mejor ingeniero de datos, que estar ya trabajando y querer hacer una transición sin prisa. Cabe mencionar el curso de 16 semanas de FourthBrain, que son maravillosos.
Dados los puntos en común que hemos venido comentando entre científico de datos e ingeniero de datos ¿Es posible tener ambos roles?
Kate comenta que no. Pone un ejemplo de otro campo para ilustrarlo mejor. Si pensamos en un científico nuclear y un ingeniero nuclear. El científico nuclear tiene que saber la ciencia que hay detrás del átomo, cómo extraemos energía del átomo y un montón de cosas más. Sin embargo, el ingeniero nuclear no tiene que saber nada de eso. Ellos saben de los materiales que se utilizan, de lo necesario para construir una planta nuclear, etc.
Shandy añade que son solo 10 años que llevamos con estos roles y que habrá que ver cómo avanza todo.
Cada vez más, tenemos herramientas que lo hacen todo. En este sentido, ¿llegará un punto en que los científicos pasarán a más bien ser ingenieros de software?
Aishwarya empieza comentando la diferencia entre cuando ella estudió ingeniería de software y ahora, que prácticamente todo el mundo sabe programar en Python y hasta los niños muy pequeños aprenden rápido a programar. La tecnología ha crecido mucho y el uso de smartphones, tablets y ordenadores portátiles es generalizado. La codificación se está convirtiendo en algo común a muchas personas, independientemente de sus estudios. Y la ciencia de datos se fusiona con la ingeniería de software en librerías como scikit u otras librerías de Python, donde las personas utilizan dos líneas de código que llevan detrás modelos sofisticados que no conocen. Esto pone la ciencia de datos al alcance de cualquiera. Sin embargo, hay otra parte de la ciencia de datos que no se puede fusionar todavía con la ingeniería de software: la ciencia de datos compleja que se aplica en las industrias. De la misma manera que las empresas están transformando sus negocios a la nube, también están transformando sus negocios en ciencia de datos. Y este tipo de modelos tan específicos, necesitan ser mejorados y trabajados por científicos de datos, antes de pasar a implementarlos y más tarde a generalizarlos. En este sentido, creo que los científicos de datos siempre van a estar ahí, desarrollando cosas nuevas, aunque la ciencia de datos se generalice y esté al alcance de cualquiera.
Con la construcción de modelos más automatizada, como acabamos de ver vía paquetes avanzados, ¿van a transformarse la ciencia de datos y el Machine Learning en puestos más especializados en base al negocio como el que procesa los datos, el que investiga, el que desarrolla el software, etc.? ¿O por el contrario será roles que cubran el proceso de comienzo a fin?
Steve dice que ambos pueden suceder. Por una parte, a medida que surgen diferentes tecnologías complejas van surgiendo especializaciones. Es similar al caso de los doctores, que hace muchos años eran doctores en general, luego surgieron especialidades, y siguieron surgiendo más y más. Algo parecido sucede en la ciencia de datos, donde hay campos en los que cada vez tenemos más preguntas y más complejas que resolver, como el tema de la explicabilidad o de la ética. Para esto se van a necesitar personas que sepan muchos y trabajen los temas particulares. Al mismo tiempo, el uso de auto Machine Learning y plataformas van a permitir que otra serie de científicos de datos e ingenieros de datos sean capaces de resolver problemas de principio a fin. Por ejemplo, en empresas pequeñas o start-up, donde van a necesitar crear un MPV (Mínimo Producto Viable) de manera ágil. Otro símil sería la creación de una página web, que se puede hacer de manera sencilla con programas fáciles como Wix o de manera muchos más compleja con especialistas.
¿Qué industrias van a ser las que más necesidades van a tener de este tipo de perfiles y donde más crecimiento va a haber?
Aishwarya cree que las empresas del cuidado de la salud, que tratan ni más ni menos que con la vida de los seres humanos, y que necesitan mucha investigación y la mejor tecnología. También las empresas que tienen algo que ver con el cambio climático y que de alguna manera puedan ayudar con los datos a mejorar la sostenibilidad del planeta.
Steve está de acuerdo con las empresas que se dedican al cuidado de la salud, y añade el sector educativo y las finanzas. Y Kate también se inclina por las empresas financieras.
Hasta aquí el debate. Espero que os haya gustado. Hubo algunas preguntas interesantes, pero ya no he querido alargar más el post ¡Qué mundo tan apasionante!


