
Random Forest es una técnica basada en árboles de decisión, que soluciona el problema que tienen los árboles de decisión de no servir para reproducir escenarios predictivos what-if.
Con el árbol de decisión veíamos qué variables podían predecir una variable objetivo determinada, pero no podíamos saber la importancia de cada variable.
Con Random Forest sí vamos a poder conocer la importancia de cada variable.
Al igual que en los árboles de decisión, la variable objetivo en un Random Forest puede ser categórica o cuantitativa. Y el grupo de variables explicativas también.
Recordar aquí cómo ejecutar Python en el ordenador.
- Programa para desarrollar Random Forest
Os dejo el código, explicando qué hace cada cosa, y señalando las cosas importantes.
#Primero hay que llamar a unas librerías que el programa necesitará.
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
import os
import matplotlib.pylab as plt
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
import sklearn.metrics
from sklearn import datasets
from sklearn.ensemble import ExtraTreesClassifier
#Después, indicamos en qué directorio vamos a trabajar. Aquí ponéis entre paréntesis vuestro directorio.
os.chdir(«C:\TREES»)
#Cargamos el fichero de datos. Formato en Excel, csv.
AH_data = pd.read_csv(«tree_addhealth.csv»)
#Eliminamos los datos con valores missing porque Python no puede hacer árboles con datos missing
data_clean = AH_data.dropna()
#Para comprobar que se ha leído bien, podemos lista las variables en el fichero y sacar los principales estadísticos
data_clean.dtypes
#Principales estadísticos
data_clean.describe()
#Indicamos las variables predictoras y debajo la variable objetivo. Cada uno con los nombres de las variables que tenéis en el fichero csv.
predictors = data_clean[[‘VARPRED1’, ‘VARPRED2′,’VARPRED3’]]
targets = data_clean.TREG1
#Creamos la muestra de entrenamiento y de test, tanto para predictores como para la variable objetivo, siendo test el 40%
pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, targets, test_size=.4)
#Importamos desde sklearn.ensamble, el algoritmo de Random Forest
from sklearn.ensemble import RandomForestClassifier
#Inicializamos el algoritmo Random Forest e indicamos el número de árboles que vamos a construir
classifier=RandomForestClassifier(n_estimators=25)
#Construimos el modelo sobre los datos de entrenamiento
classifier=classifier.fit(pred_train,tar_train)
#Predecimos para los valores del grupo Test
predictions=classifier.predict(pred_test)
#Pedimos la matriz de confusión de las predicciones del grupo Test. La diagonal de esta matriz se lee: arriba a la izda True Negatives y abajo a la dcha True Positives.
sklearn.metrics.confusion_matrix(tar_test,predictions)
#Sacamos el índice Accuracy Score, que resume la Matriz de Confusión y la cantidad de aciertos.
sklearn.metrics.accuracy_score(tar_test, predictions)
#Para obtener la importancia de cada variable inicializamos el ExtraTreesClassifier
model = ExtraTreesClassifier()
#Ajustamos el modelo
model.fit(pred_train,tar_train)
#Pedimos que nos muestre la importancia de cada variable
print(model.feature_importances_)
#Si queremos ver todas las variables en caso de ser muchas, mejor usar el comando «list»
list(model.feature_importances_)
#Para dibujar todos las variables con su importancia
from matplotlib import pyplot
pyplot.bar(range(len(model.feature_importances_)), model.feature_importances_)
pyplot.show()
#Para ver cuánto ha aportado cada nuevo árbol que hemos construido
trees=range(25)
accuracy=np.zeros(25)
for idx in range(len(trees)):
classifier=RandomForestClassifier(n_estimators=idx + 1)
classifier=classifier.fit(pred_train,tar_train)
predictions=classifier.predict(pred_test)
accuracy[idx]=sklearn.metrics.accuracy_score(tar_test, predictions)
plt.cla()
plt.plot(trees, accuracy)
- Salida en Python y lectura
Se obtiene el listado de las variables con su importancia. En este listado prima el orden en que se escribieron las variables en el programa: VAR1, VAR2,…
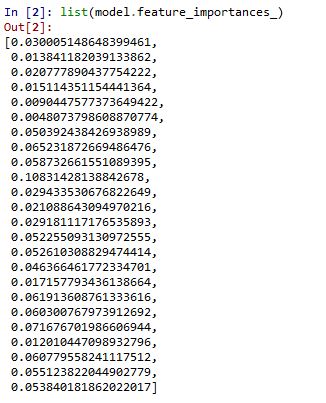
También se puede hacer un gráfico de estas variables y su importancia:
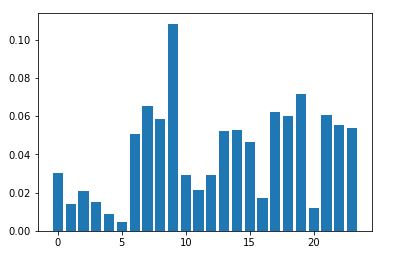
Por último, obtenemos el gráfico que nos indica si los árboles que se tuvieron que construir fueron suficientes o no:
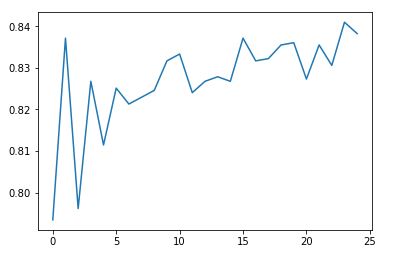
Como punto negativo, en Random Forest no se interpretan los árboles que se construyen. Lo que obtenemos es solamente la importancia de las variables explicativas.
Random Forest se utiliza solo para clasificar la importancia de las variables en la predicción de la variables objetivo.
Sabemos cuales son las variables predictivas más importantes, pero no necesariamente sus relaciones entre sí.



Comentarios